Transformer Model
Table of Contents
A Transformer Model is a type of neural network architecture specifically designed for processing sequential data, such as text.
In the field of natural language processing (NLP), the Transformer model has emerged as an innovative technology that has changed the way machines understand and generate human language.
Developed by researchers at Google in 2017, this model has since become the cornerstone of many state-of-the-art NLP applications, including language translation, sentiment analysis, and text generation.
What are Transformers?
This is a type of neural network architecture specifically designed for processing sequential data, such as text.
Unlike traditional sequence-to-sequence models, which rely on recurrent neural networks (RNNs) or long short-term memory (LSTM) units to capture sequential dependencies, the Transformer model uses a self-attention mechanism to learn representations of words in a sequence simultaneously.
The key innovation of this technology lies in its attention mechanism, which allows the model to weigh the importance of each word in a sequence relative to the others.
By attending to different parts of the input sequence, the Transformer model can capture long-range dependencies and contextual information more effectively than traditional recurrent models.
Architecture of the Transformer Model
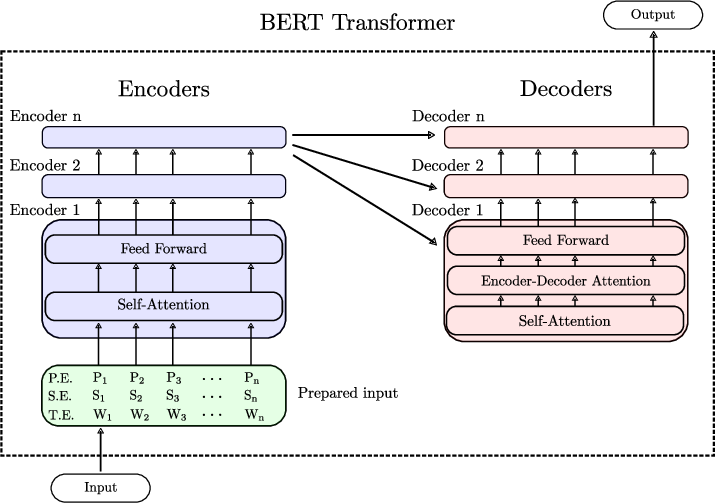
The Transformer model consists of two main components: the encoder and the decoder.
The encoder takes an input sequence of tokens and processes it into a set of hidden representations, while the decoder generates an output sequence based on the encoder’s representations.
The encoder is composed of multiple layers of self-attention mechanisms, followed by feedforward neural networks.
Each layer in the encoder processes the input sequence independently and passes its output to the next layer.
The self-attention mechanism allows the model to capture contextual information from the entire input sequence, making it more effective at handling long-range dependencies.
The decoder, on the other hand, is similar to the encoder but includes an additional attention mechanism that helps it generate the output sequence one token at a time.
The decoder uses the encoder’s representations to attend to different parts of the input sequence and generate the output tokens based on the context provided by the encoder.
Training the Transformer Model
Training the Transformer model involves optimizing its parameters to minimize a loss function, typically the cross-entropy loss between the predicted and actual output sequences.
The model is trained using backpropagation and gradient descent algorithms, where the gradients are computed using automatic differentiation techniques.
One of the key advantages of the Transformer model is its parallelizability, which allows it to process input sequences in parallel rather than sequentially.
This makes training the model more efficient and reduces the time required to train on large datasets.
Applications of the Transformer Model
The model has been widely adopted in a variety of NLP tasks, including language translation, sentiment analysis, text summarization, and question-answering.
One of the most popular implementations of the Transformer model is the Transformer-XL, a variant that extends the original model to handle longer sequences more effectively.
In language translation, the Transformer model has achieved state-of-the-art performance on benchmark datasets such as the WMT’14 English-German and English-French translation tasks.
By learning representations of words in both the source and target languages simultaneously, the model can effectively capture the nuances of language and produce accurate translations.
In sentiment analysis, the Transformer model has been used to classify text based on its emotional content, such as positive or negative sentiment.
By attending to different parts of the input sequence, the model can capture subtle cues and nuances that traditional models may miss.
Final Thoughts
The Transformer model has revolutionized the field of natural language processing by introducing a new paradigm for processing sequential data.
Its self-attention mechanism allows the model to capture long-range dependencies and contextual information more effectively than traditional sequence-to-sequence models, leading to state-of-the-art performance on a variety of NLP tasks.
As researchers continue to explore the capabilities of the technology, we can expect to see even more advancements in NLP applications, such as language translation, sentiment analysis, and text generation.
With its powerful architecture and parallelizability, the Transformer model is poised to shape the future of NLP and drive innovation in artificial intelligence.
Image credit:
Source: Research Gate




